Định nghĩa Big Data và nhận dạng Big Data như thế nào?
Ở thời đại 4.0, chúng ta vẫn thường hay nghe người ta nhắc đến Big Data, đến AI, Machine Learning,....vậy thì đi từ một khái niệm vẫn thường hay nói với nhau nhất là Big Data, nó thực sự là gì và làm sao để biết dữ liệu kiểu nào được gọi là Big Data?
Bản thân mình thực sự cũng cứ nói bâng quơ nhưng chưa bao giờ thực sự hiểu được về nó, và hôm qua mới có một cái nhìn tổng quan nên muốn chia sẻ cho mọi người.
Định nghĩa Big Data
Big Data có thể coi là một tệp dữ liệu có độ lớn đến mức mà vượt ra ngoài khả năng của các công cụ phần mềm thông thường để lưu giữ, quản lý và phân tích.
Khái niệm này thực chất đã có gắn khía cạnh thời gian trong đó. Các công cụ phần mềm thông thường ở đây áp dụng cho khả năng hiện tại của công nghệ. Vì vậy, những gì chúng ta gọi là Big Data ở 10 năm trước không có nghĩa sẽ là Big Data ở thời điểm hiện tại vì các công cụ thông thường và công nghệ đã thay đổi.
Nhận dạng Big Data thông qua 4Vs
Để nhận dạng một tệp dữ liệu có phải là "lớn" hay không, chúng ta có thể nhận dạng thông qua 4 khía cạnh đặc điểm là Volume (Độ lớn), Variety (Độ đa dạng), Velocity (Tốc độ), và Veracity (Tính xác thực).
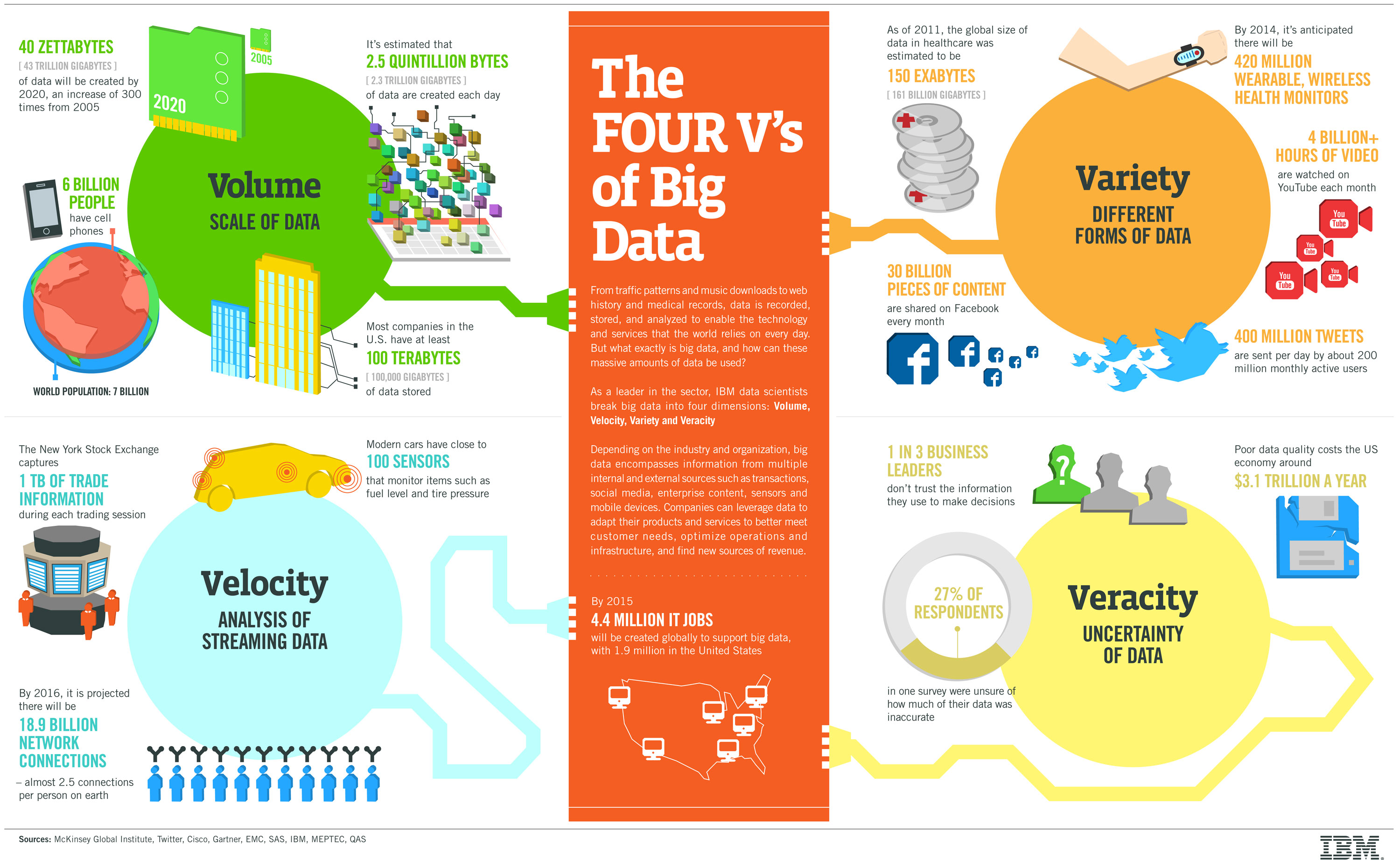
Nguồn IBM
Volume (Độ lớn)
Độ lớn ở dây chính là số lượng dữ liệu có bị lưu trữ. Ví dụ về dữ liệu của Walmart, họ có thể xử lý hơn 1 triệu giao dịch người dùng mỗi giờ, và đưa vào kho dữ liệu của họ hơn 2,5 petabytes (2,5 triệu Gbs). Để quản lý độ lớn của dữ liệu, thường có 2 cách:
- Mở rộng quy mô: Giữ nguyên số lượng hệ thống lưu trữ và xử lý dữ liệu, nhưng mở rộng hơn mỗi hệ thống
- Tăng số lượng: Giữ nguyên độ rộng mỗi hệ thống và tăng số lượng hệ thống lên
Velocity (Tốc độ)
Tốc độ trong Big Data là tốc độ khi dữ liệu được đưa vào một hệ thống và được xử lý. Tốc độ là một yếu tố quan trọng trong xử lý các luồng dữ liệu. Thử nghĩ xem nếu tất cả dữ liệu từ nhận dạng tần số vô tuyến (RFID), hệ thống định vị toàn cầu (GPS), giao tiếp trường gần (NFC) và cảm biến Bluetooth tràn vào hệ thống. Xử lý các luồngdữ liệu nhằm mục đích tổng hợp lại từng điểm dữ liệu từ dữ liệu tốc độ cao, để sử dụng cho một hoạt động ở mức cao khi tìm ra mẫu chắc chắn. Nó cũng giúp cho việc quyết định giữ lại những dữ liệu nào từ một luồng vì không thể giữ lại tất cả dữ liệu đang đổ xô vào.
Variety (Đa dạng)
Sự đa dạng chính là độ đa dạng của các định dạng dữ liệu. Big Data bao gồm các định dạng dữ liệu khác nhau. Ví dụ khi một công ty viễn thông ghi lại dữ liệu về các cuộc gọi đến trung tâm cuộc gọi của mình, dữ liệu này có thể bao gồm:
- Dữ liệu có cấu trúc, phù hợp với mô hình dữ liệu được xác định trước (ví dụ: ID khách hàng của bạn, dấu thời gian của cuộc gọi, loại dịch vụ của bạn)
- Dữ liệu phi cấu trúc (ví dụ: bản ghi âm cuộc gọi, được thực hiện trong khi gọi)
Veracity (Xác thực)
Độ xác thực ở đây là độ tin cậy của dữ liệu. Càng nhiều dữ liệu được thu thập và phân tích tự động nhưng không được ghi lại đầy đủ nhất thì độ không chắc chắn về độ chính xác của dữ liệu càng cao. Ví dụ, rất khó để xác minh tính trung thực của các nội dung trên các nền tảng truyền thông xã hội như reviews, tin tức, vì chúng ta không phải lúc nào cũng biết các thông tin về các nhà làm quảng cáo và ý định của họ. Trên thực tế, phát hiện các reviews giả, tin tức giả và người dùng giả hiện đang là một lĩnh vực nghiên cứu phổ biến.
Trên đây là 4 yếu tố thường thấy để nhận dạng ra Big Data. Bên cạnh đó, đối với một số dữ liệu khác thì cần có những yếu tố đặc thù hơn. Mình cũng là một đứa rất ngu về mấy cái công nghệ các kiểu như này nên mong có thể nhận được góp ý, gợi ý về các nguồn hay ho uy tín để tìm hiểu thêm.
--
Nguồn:
- Mckinsey
- Database Systems: Design, Implementation, and Management
- Fundamentals of database system
Copyright: Griffith University