Hệ thống đề xuất bài hát của Zing MP3
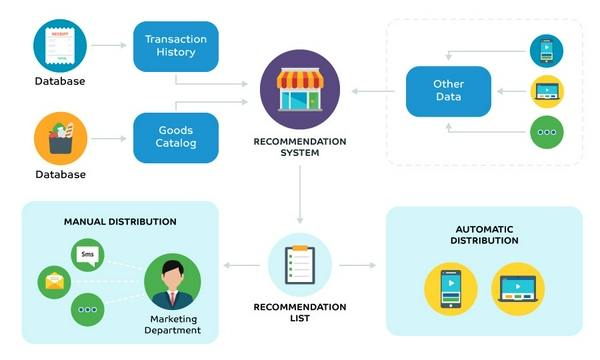
Tại sao lại là Recommendation System?
Với số lượng ngày càng tăng của các giao dịch thương mại điện tử trên internet và với số lượng lớn các lựa chọn có sẵn cho người dùng, cần phải sàng lọc và phân tích thông tin có liên quan về người dùng và các mặt hàng. Hệ thống đề xuất khai thác tùy chọn và đặc điểm của người dùng để ưu tiên và đề xuất các sản phẩm mà người dùng muốn.
Hệ thống khuyến nghị là một giá trị gia tăng lớn cho các công ty lớn như Google, Amazon, Facebook, Netflix, Zing MP3,... khi họ thúc đẩy sự tham gia và doanh thu đáng kể của khách hàng. Các nhà phân tích dữ liệu ước tính rằng đã có 35% những gì người tiêu dùng mua trên Amazon và 75% những gì họ xem trên Netflix đến từ các khuyến nghị sản phẩm dựa trên các thuật toán đề xuất. Hệ thống này không chỉ khai thác người dùng bằng cách lôi kéo họ mua nhiều sản phẩm và dịch vụ hơn theo sở thích của họ mà còn giữ họ tham gia lâu hơn để hiển thị cho họ nhiều quảng cáo hơn và có được nhiều khách hàng hơn.
Recommendation Systems là gì?
Recommendation Systems (hệ thống khuyến nghị) còn được gọi là hệ thống giới thiệu hoặc công cụ giới thiệu. Có rất nhiều định nghĩa có sẵn trên internet. Tuy nhiên, một định nghĩa có vẻ dễ hiểu là:
"Hệ thống đề xuất là hệ thống giúp người dùng khám phá các mục mà họ có thể thích"
Hệ thống đề xuất có vô số các ứng dụng như đề xuất sản phẩm (như phim ảnh và video, sách, mặt hàng thời trang,...), đề xuất các bài báo, bài đăng công việc, bạn bè trên Facebook
Các loại Recommendation Systems
Popularity-based
Đây chỉ đơn giản là đề nghị các mặt hàng phổ biến nhất cho người dùng. Popularity-based systems đơn giản nhất và có các yêu cầu tính toán ít. Tuy nhiên, vì các hệ thống này không đưa ra các đề xuất được cá nhân hóa dựa trên những hành vi của người dùng cụ thể, chúng có xu hướng kém chính xác hơn so với content-based hoặc collaborative filtering based.
Content-based/ Context-based
Content-based khai thác các thuộc tính / đặc trưng của người dùng và đề xuất các mục phù hợp với người dùng. Các hệ thống này phù hợp trong các ứng dụng mà thông tin theo ngữ cảnh dễ dàng nhận được. Ngoài ra, không giống như collaborative filtering, chúng không phụ thuộc vào phản hồi (feedback) hay xếp hạng (rangking) của người dùng.
Ví dụ:
Cho phép nói rằng chúng tôi có hai thuộc tính có tên là Romance và Action - thể loại phim. Người dùng cũng có thể được lược tả dựa trên các tùy chọn cho các tính năng này. Do đó, các ma trận User-feature và Movie-feature được đưa ra dưới đây
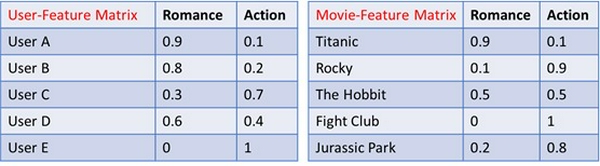
Bây giờ để dự đoán xếp hạng mà người dùng sẽ cung cấp cho mỗi bộ phim, 'dấu chấm' được hiểu là người dùng được 'ánh xạ' đến một bộ phim. Vì vậy, ví dụ, nếu chúng ta cần dự đoán người dùng A đã xếp loại phim nào cho Titanic, nó có thể được viết như sau:
User A ∙ Titanic = User A’× Titanic (= 0.9*0.9+0.1*0.1 = 0.82)
Tương tự cho người dùng và phim khác cũng theo công thức trên. Các xếp hạng có thể được chuẩn hóa hoặc thu nhỏ hơn nữa và điều chỉnh cho các đánh giá của người dùng có thể được thực hiện. Như vậy, nó là hiển nhiên từ bảng dưới đây Titanic là khuyến nghị tốt nhất cho người dùng A, trong khi đối với người dùng E, Fight Club và Rocky là hai khuyến nghị hàng đầu.

Các hệ thống Content-based phụ thuộc vào thông tin bên ngoài để tạo hồ sơ người dùng và thông tin này có thể không dễ dàng có sẵn. Ngoài ra, các thông tin này không tính đến thông tin hành vi của người dùng và giảm giá thực tế là sở thích và "sở thích của người dùng có thể thay đổi theo thời gian".
3 dạng ngữ cảnh phổ biến thường được phân tích là thời gian (time-sensitive awared), địa điểm (location awared) và tương tác xã hội (social-network awared).
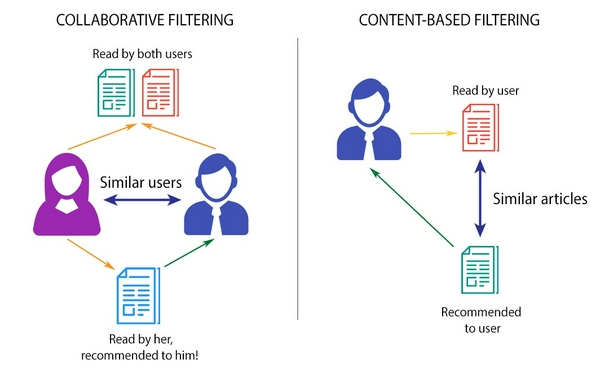
Collaborative Filtering
Collaborative Filtering dựa trên việc thu thập và phân tích thông tin hành vi của người dùng theo các phản hồi, xếp hạng, sở thích và hoạt động của họ. Dựa trên thông tin này, các thông tin này sau đó khai thác sự tương đồng giữa một số người dùng để dự đoán các xếp hạng bị thiếu và sau đó đưa ra các khuyến nghị phù hợp. Collaborative Filtering có thể tự khám phá và tìm hiểu các tính năng mà không cần các tính năng rõ ràng cho các mục hồ sơ hoặc người dùng.
Memory-based/ Neighborhood-based
- User-based
Khái niệm chính ở đây là xác định người dùng, đại khái như mục tiêu của hệ thống là người dùng A và để đề xuất xếp hạng cho xếp hạng không được giám sát của A bằng cách tính toán mức trung bình có trọng số của xếp hạng của nhóm này.
Ví dụ:
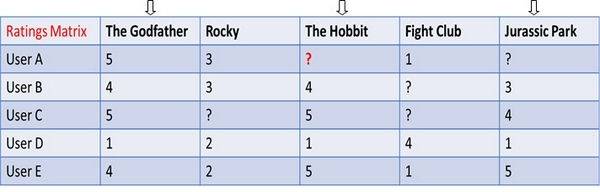
Giả sử chúng ta cần tìm xem người dùng A có thích bộ phim “The Hobbit” hay không. User-based tìm người dùng n đã xếp hạng phim tương tự như người dùng A. Lưu ý rằng trong bảng bên dưới, người dùng C và người dùng E đã xếp hạng phim theo kiểu thời trang tương tự như người dùng A. Trong thực tế, các phép đo giống như

- Item-based
Ví dụ:
Giả sử chúng ta cần tìm xem người dùng A có thích bộ phim “The Hobbit” hay không. Cách tiếp cận dựa trên mặt hàng tìm thấy n phim đã được đánh giá tương tự như The Hobbit bởi những người dùng khác. Lưu ý rằng trong bảng dưới đây, xếp hạng của người dùng cho The Godfather và Jurassic Park tương tự như The Hobbit. Để dự đoán xếp hạng mà người dùng A sẽ cung cấp cho The Hobbit, một tỷ lệ trung bình có trọng số của các phim tương tự nhất được lấy. Các chỉ số tương tự như
Model-based/Matrix Factorization
Bài toán khuyến nghị có thể được đưa về bài toán dự đoán xác suất P(a,i) người dùng A thích phim I (hoặc không). Đối với các dạng bài toán này, các tham số của mô hình được học trong ngữ cảnh tối ưu cho việc dự đoán xác suất P(a,i).
Việc chọn model phụ thuộc vào từng bài toán và dữ liệu cụ thể. Có thể ví dụ một vài model phổ biến như Decision Trees, Rule-based Models, Bayesian hay Latent Factor Models … hay như gần gây là Deep Learning. Việc đưa bài toán về dạng model-based có thể tận dụng được rất nhiều giải thuật Prediction hoặc Classification.
Theo góc nhìn này, memory-based cũng là một dạng đặc biệt của model-based, dự đoán xác suất người dùng A thích phim I dựa vào đặc trưng là đánh giá của các người dùng và phim tương tự.
Hybrid Approach
Memory-based và Model-based là các phương pháp tiếp cận có thể được kết hợp trong thực tế để khai thác các lợi ích mà mỗi phương pháp tiếp cận cung cấp. Ngoài ra, content-based và collaborative filtering cũng có thể được kết hợp theo nhiều cách khác nhau để đạt được hiệu quả gợi ý tối ưu.
Ví dụ bài toán thực tế - Hệ thống đề xuất bài hát của Zing MP3
Hệ thống khuyến nghị đang được sử dụng cho Zing MP3 là một hybrid system, kết hợp giữa Collaborative Filtering và Content-Based. Collaborative Filtering models dựa vào lịch sử nghe để tìm kiếm các bài hát được nghe giống nhau bởi các tập users giống nhau. Trong khi đó, NLP models phân nhóm các bài hát dựa vào các thông tin metadata như title, playlist, ca sĩ, nhạc sĩ, etc.
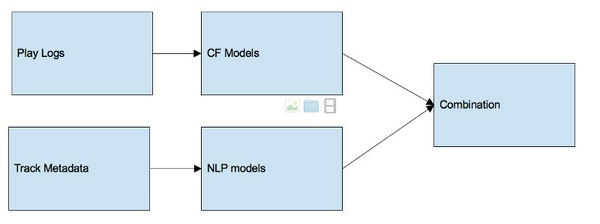
Việc kết hợp hai nguồn thông tin, hai loại giải thuật khác nhau mang lại nhiều lợi ích:
● Tận dụng được nhiều features khác nhau, tăng tính chính xác.
● Tăng cường độ đa dạng, các bài hát mới vẫn có cơ hội được giới thiệu.
● Cách tổng hợp kết quả của các models được điều chỉnh theo feed-back của users.
Data Flow
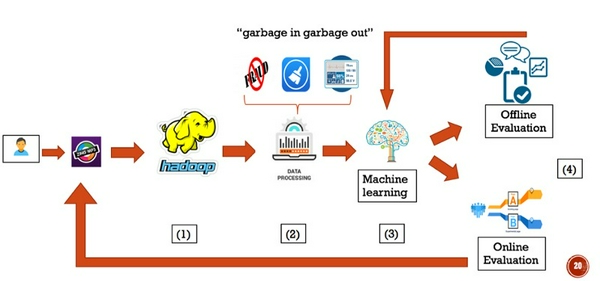
Dữ liệu tương tác (log) của người dùng lên Zing Mp3 từ nhiều platforms khác nhau (web lẫn mobile) được tập trung và lưu trữ vào Hadoop (1). Tiếp đó dữ liệu sẽ đi qua hệ thống tiền xử lý (2). Tại đây, dữ liệu được làm sạch, loại bỏ nhiễu, abnormal, cũng như rút trích các đặc tính phù hợp, sau đó đi vào hệ thống learning (3).
Model được sinh ra trong learning sẽ được đánh giá offline đến khi đạt được độ chính xác cần thiết trước khi đưa ra thực tế. Hệ thống đánh giá online sử dụng A/B testing đo lường hành vi của user lên các giải thuật khác nhau, từ đó tinh chỉnh lại giải thuật, hoặc rút trích thêm các đặc tính cho phù hợp hơn.
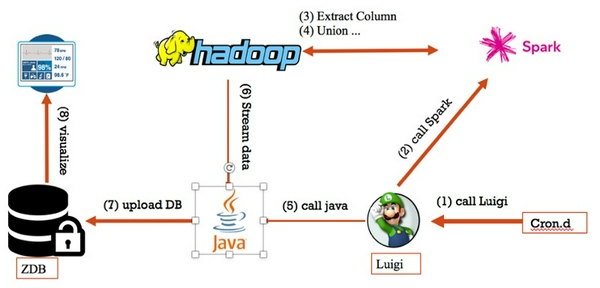
Data processing
Hệ thống tiền xử lý dữ liệu của ZingMp3 bao gồm Luigi, một framework được phát triển bởi Spotify để quản lý luồng dữ liệu. Luigi được định thời gọi các Spark jobs để rút trích, tổng hợp dữ liệu được lưu trong Hadoop. Dữ liệu được xử lý sẽ đi qua hệ thống mô tả để dễ dàng giám sát.
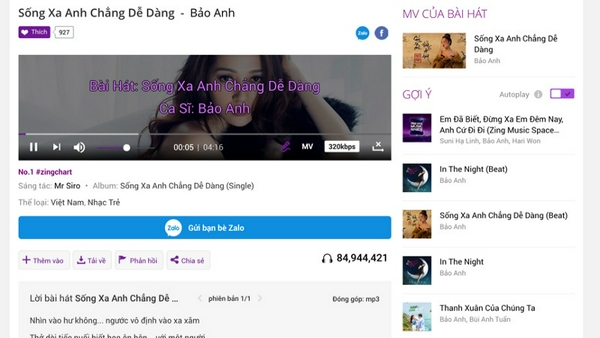
Một số kết quả
Một số kết quả được hiển thị bên dưới. Các bài hát được giới thiệu có sự liên quan với nhau và giống với bài hát đang được nghe. Các bài hát khá đa dạng. Các danh sách bài hát được gợi ý đang đóng góp 31% lượt nghe các bài hát trên website Zing MP3.
Nguồn:

blog
,recommendation system
,bigdata
,machine lear
,zing mp3
,trí tuệ nhân tạo
Nhờ có hệ thống này là chỉ cần vào ví dụ như sendo.vn tìm pin mặt trời là đi đâu cũng thấy đề xuất pin mặt trời, đủ loại đủ kiểu. 😂😂
Nguyễn Quang Vinh
Nhờ có hệ thống này là chỉ cần vào ví dụ như sendo.vn tìm pin mặt trời là đi đâu cũng thấy đề xuất pin mặt trời, đủ loại đủ kiểu. 😂😂