Chia sẻ về Mạng nơ-ron tích chập (Convolutional Neural Networks or ConvNEts)
Cập nhật series này tại:

Với sự phát triển phần cứng mạnh mẽ cho phép tính toán song song hàng tỉ phép tính, tạo tiền đề cho Mạng nơ-ron tích chập trở nên phổ biến và đóng vai trò quan trọng trong sự phát triển của trí tuệ nhân tạo nói chung và xử lý ảnh nói riêng. Một trong các ứng dụng quan trọng của mạng nơ-ron tích chập đó là cho phép các máy tính có khả năng “nhìn” và “phân tích”, nói 1 cách dễ hiểu, Convnets được sử dụng để nhận dạng hình ảnh bằng cách đưa nó qua nhiều layer với một bộ lọc tích chập để sau cùng có được một điểm số nhận dạng đối tượng. CNN được lấy cảm hứng từ vỏ não thị giác.
Mỗi khi chúng ta nhìn thấy một cái gì đó, một loạt các lớp tế bào thần kinh được kích hoạt, và mỗi lớp thần kinh sẽ phát hiện một tập hợp các đặc trưng như đường thẳng, cạnh, màu sắc,v.v.v của đối tượng. lớp thần kinh càng cao sẽ phát hiện các đặc trưng phức tạp hơn để nhận ra những gì chúng ta đã thấy.
Bài viết này sẽ trình bày một cách ngắn gọn về Mạng nơ-ron tích chập, vì là một bài ngắn gọn, mình sẽ viết một cách đơn gián nhất để cho những bạn chỉ mới biết căn bản của học máy hay chưa từng biết gì về xử lý ảnh cũng có thể nắm bắt được tư tưởng của mạng tích chập. Chi tiết hơn cho mỗi phần mình sẽ viết cụ thể ở các bài sau.
ConvNet có 02 phần chính: Lớp trích lọc đặc trưng của ảnh (Conv, Relu và Pool) và Lớp phân loại (FC và softmax).
Đầu vào (dữ liệu training):
- Input đầu vào là một bức ảnh được biểu diển bởi ma trận pixel với kích thước: [w x h x d]
- W: chiều rộng
- H: chiều cao
- D: Là độ sâu, hay dễ hiểu là số lớp màu của ảnh. Ví dụ ảnh RBG sẽ là 3 lớp ảnh Đỏ, Xanh Dương, Xanh.

(Channels của ảnh RBG và ảnh xám)
Conv Layer:
Mục tiêu của các lớp tích chập là trích chọn các đặc trưng của ảnh đầu vào.
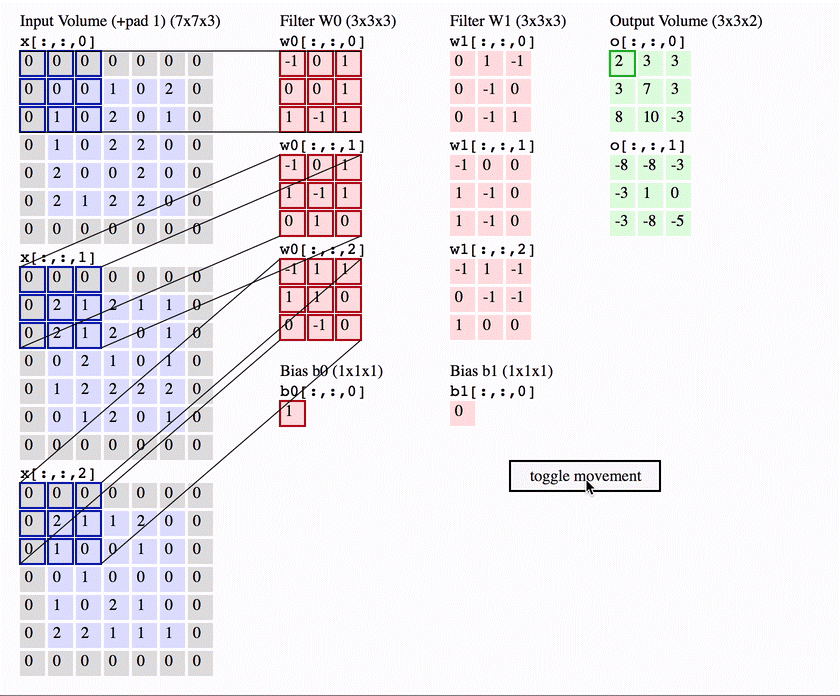
Ví dụ của Conv layer. (Nguồn : CS231n notes.)
Ảnh đầu vào được cho qua một bộ lọc chạy dọc bức ảnh. Bộ lọc có kích thước là (3x3 hoặc 5x5) và áp dụng phép tích vô hướng để tính toán, cho ra một giá trị duy nhất. Đầu ra của phép tích chập là một tập các giá trị ảnh được gọi là mạng đặc trưng (features map).
Thực chất, ở các layer đầu tiên, phép tích chập đơn giản là phép tìm biên ảnh, nếu các bạn có kiến thức cơ bản về xử lý ảnh. Còn nếu không thì bạn chỉ cần hiểu sau khi cho qua bộ lọc nó sẽ làm hiện lên các đặc trưng của đối tượng trong ảnh như đường vẽ xung quanh đối tượng, các góc cạnh,v.v.., và các layer tiếp theo sẽ lại trích xuất tiếp các đặc trưng của đặc trưng của các đối tượng đó, việc có nhiều layer như vậy cho phép chúng ta chia nhỏ đặc trưng của ảnh tới mức nhỏ nhất có thể. Vì thế mới gọi là mạng đặc trưng.
Dưới đây là một số các khái niệm cơ bản của phần này:
Filter, Kernel hay Feature Detector đều là cách gọi của ma trận lọc (như mình đã đề cập ở trên). Thông thường, ở các lớp đầu tiên của Conv Layer sẽ có kích thước là [5x5x3]
Convolved Feature, Activation Map hay Feature Map là đầu ra của ảnh khi cho bộ lọc chạy hết bức ảnh với phép tích vô hướng.
Receptive field là vùng ảnh được chọn để tính tích chập, hay bằng đúng cái kích thước của bộ lọc.
Depth là số lượng bộ lọc. Lưu ý: ở đây là số lượng bộ lọc (filter) chứ không phải số lượng kênh màu RBG như ở trên.
Stride được hiểu là khoảng cách dịch chuyển của bộ lọc sau mỗi lần tính. Ví dụ khi stride=2. Tức sau khi tính xong tại 1 vùng ảnh, nó sẽ dịch sang phải 2 pixel. Tương tự với việc dịch xuống dưới
Zero-Padding là việc thêm các giá trị 0 ở xung quanh biên ảnh, để đảm bảo phép tích chập được thực hiện đủ trên toàn ảnh.
Vậy kích thước đầu ra của ảnh với mỗi layer được tính như thế nào?
Giả sử ảnh đầu ra là [W2 x H2 x D2]
Thì:
W2 = (W1 – F + 2P) / S + 1
H2 = (H1 – F +2P) / S + 1
D2 = K
Trong đó:
[W1xH1xD1]: Kích thước đầu vào
F: Kích thước bộ lọc Kernel
S: giá trị Stride
P: số lượng zero-padding thêm vào viền ảnh
K: Số lượng bộ lọc (Depth)
Ví dụ:
Kích thước đầu ra của lớp đầu tiên trong kiến trúc mạng học sâu nơ-ron tích chập (Deep Convolutional Neural Networks) đã từng chiến thắng ImageNet Chanllenge 2012 là:
Đầu vào: [227x227x3], W=227, F=11, S=4, P=0, and K=96.
Đầu ra:
(227 - 11) / 4 + 1 = 55
Vậy kích thước đầu ra của layer đầu tiên là [55x55x96].
ReLU Layer:
ReLU layer áp dụng các kích hoạt (activation function) max(0,x) lên đầu ra của Conv Layer, có tác dụng đưa các giá trị âm về thành 0. Layer này không thay đổi kích thước của ảnh và không có thêm bất kì tham số nào.
Mục đích của lớp ReLu là đưa ảnh một mức ngưỡng, ở đây là 0. Để loại bỏ các giá trị âm không cần thiết mà có thể sẽ ảnh hưởng cho việc tính toán ở các layer sau đó.
Pool Layer:
Pool Layer thực hiện chức năng làm giảm chiều không gian của đầu và giảm độ phức tạp tính toán của model ngoài ra Pool Layer còn giúp kiểm soát hiện tượng overffiting. Thông thường, Pool layer có nhiều hình thức khác nhau phù hợp cho nhiều bài toán, tuy nhiên Max Pooling là được sử dụng nhiều vào phổ biến hơn cả với ý tưởng cũng rất sát với thực tế con người đó là: Giữ lại chi tiết quan trọng hay hiểu ở trong bài toán này chính giữ lại pixel có giá trị lớn nhất.
Ví dụ: Max pooling với bộ lọc 2x2 và stride = 2. Bộ lọc sẽ chạy dọc ảnh. Và với mỗi vùng ảnh được chọn, sẽ chọn ra 1 giá trị lớn nhất và giữ lại.
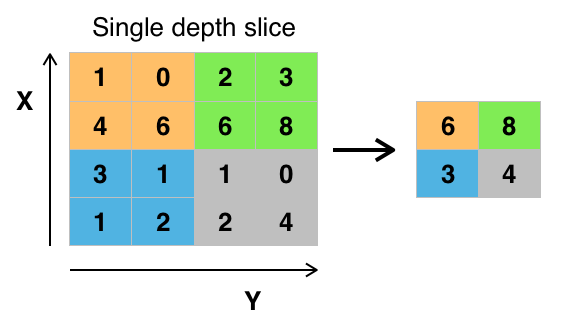
Max pooling kernel 2x2, stride = 2. Nguồn: Wikipedia
Thông thường max pooling có kích thước là 2 và stride=2. Nếu lấy giá trị quá lớn, thay vì giảm tính toán nó lại làm phá vỡ cấu trúc ảnh và mất mát thông tin nghiêm trọng. Vì vậy mà một số chuyên gia không thích sử dụng layer này mà thay vào đó sử dụng thêm các lớp Conv Layer và tăng số stride lên mỗi lần.
Fully_Connected Layer (FC):
Tên tiếng viết là Mạng liên kết đầy đủ. Tại lớp mạng này, mỗi một nơ-ron của layer này sẽ liên kết tới mọi nơ-ron của lớp khác. Để đưa ảnh từ các layer trước vào mạng này, buộc phải dàn phẳng bức ảnh ra thành 1 vector thay vì là mảng nhiều chiều như trước. Tại layer cuối cùng sẽ sử dụng 1 hàm kinh điển trong học máy mà bất kì ai cũng từng sử dụng đó là softmax để phân loại đối tượng dựa vào vector đặc trưng đã được tính toán của các lớp trước đó.
Trên đây là tóm tắt kiến trúc cơ bản của một mạng tích chập, trên thực tế sẽ có nhiều kiến trúc phức tạp hơn rất nhiều với độ chính xác gần như con người trong các cuộc thi nhận diện ảnh trên thế giới. Mình sẽ viết các bài tiếp theo kĩ hơn vào từng phần và giới thiệu cho các bạn các kiến trúc mới.
Còn ở bài viết này, bạn cũng đã có thể hoàn thành được một mạng nơ-ron đơn giản để có thể nhận dạng đối tượng đòi hỏi không quá cao như chữ viết tay, con vật, đồ vật, v.v..
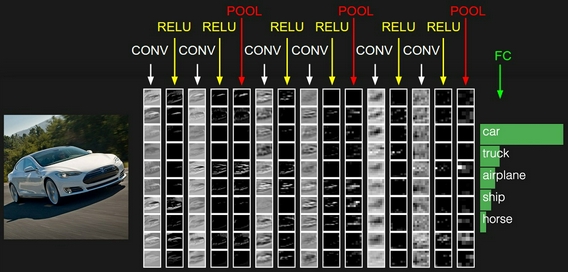
Mình sẽ giới thiệu một kiến trúc đơn giản như sau cho bộ dữ liệu CIFAR-10:
CIFAR-10 classification [INPUT — CONV — RELU — POOL — FC]
Bài viết này mình đã đầu tư khá nhiều thời gian, tuy nhiên do kiến thức vẫn còn hạn hẹp, hy vọng sẽ được mọi người ủng hộ và góp ý. Hẹn gặp lại các bạn ở những bài viết tiếp theo! :D
P/S:
Nếu mọi người có những thắc mắc về CNN, vui lòng để lại cmt phía dưới, chúng ta sẽ cùng trao đổi thảo luận sâu hơn :D
Bài viết có tha
m khảo nội dung từ:
Convolutional
Neural Networks (CNN, or ConvNets) - Medium
ai
,machine learning
,neural network
,mạng nơ ron
,học máy
,trí tuệ nhân tạo
Bài viết này rất chi tiết và có đầu tư. Mình đọc trên cuốn Deep Learning for Computer vision with Python của Adrian Rosebrock thì ông ta gọi RELU là thuật toán hay dùng nhất của lớp Activation. Ngoài ra, cũng như bài viết của bạn, Adrian cũng khuyên bỏ hẳn lớp Pooling mà sử dụng kết hợp lớp Convolutional và Activation nhưng không nói rõ lý do là để không bị mất mát thông tin nghiêm trọng như bạn đề cập.
Cảm ơn về công sức mà bạn đã bỏ ra.
An Nguyen
Bài viết này rất chi tiết và có đầu tư. Mình đọc trên cuốn Deep Learning for Computer vision with Python của Adrian Rosebrock thì ông ta gọi RELU là thuật toán hay dùng nhất của lớp Activation. Ngoài ra, cũng như bài viết của bạn, Adrian cũng khuyên bỏ hẳn lớp Pooling mà sử dụng kết hợp lớp Convolutional và Activation nhưng không nói rõ lý do là để không bị mất mát thông tin nghiêm trọng như bạn đề cập.
Cảm ơn về công sức mà bạn đã bỏ ra.
Ngô Thành