Introduction to Spark (Part 2 of 2)
Phần này tôi sẽ giới thiệu chi tiết về các các làm việc và lập trình với spark, chủ yếu sẽ là phần làm việc với RDD, pairRDD (key-value)
Nội dung
1. Làm việc với RDD
2. Làm việc với Pair RDD
3. Các nội dung chuyên sâu
4. Kết luận
1. Làm việc với RDD
RDD đơn giản là một tập hợp các phần tử không thể thay đổi được phân tán. Phần tử ở đây có thể là các đối tượng trong Java, Scala, Python hay do người dùng định nghĩa. Một RDD được chia thành nhiều partitions để dễ dàng lưu trữ, nhằm tính toán phân tán trên các nodes.
a. Tạo một RDD (Resilient Distributed Dataset)
Có 2 cách tạo RDD:
* Sử dụng phương thức parallelize() lên một collection tồn tại bên trong chương trình.
* Đọc từ nguồn bên ngoài - Spark làm việc được với các định dạng file: text File, JSON, CSV, Sequences Files (Spark) ... Từ các nguồn local hay phân tán như HDFS, Amazon S3, … Hay đọc từ các distributed database như Cassandra, Hbase, JDBC, ...
b. Phân loại các thao tác (operation) với RDD
Có 2 loại thao tác chính với một RDD là Transformation và Action.
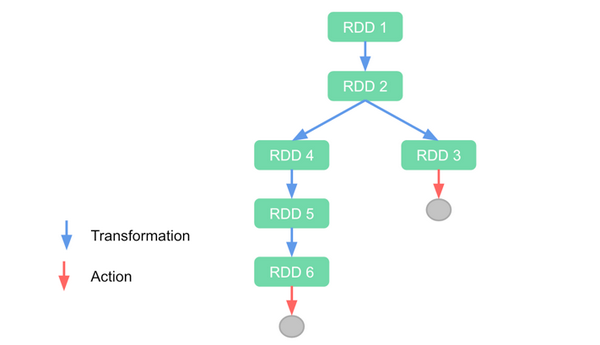
Transformation:
- Thực hiện transformation trên RDD là ta tạo ra một RDD mới. Do RDD là không thể thay đổi.
- Các phần tử chứa trong RDD mới chỉ được tính toán khi RDD đó thực hiện một trong các thao tác Actions. Do nguyên lý tính toán Lazy evaluation của Spark.
- Các thao tác transformation trên một RDD:
- map(), flatmap(), filter(), distinct(), sample(), …
- Các thao tác transformation trên nhiều RDD:
- union(), intersection(), subtract(), cartesian(), ...
Action:
- Actions là các thao tác trả về giá trị cuối cùng cho chương trình chính hoặc ghi dữ liệu ra ngoài.
- Actions khiến các transformation liên quan tạo ra RDD hiện tại thực sự thực hiện tính toán.
- Các thao tác Actions trên RDD: collect(), count(), take(), top(num), top(), fold(), countByValue(), …
- Thực hiện persistence (caching) trên RDD dùng để tính toán ra nhiều RDD khác.
Lưu ý: Khi thực hiện thao tác collect() thao tác này sẽ thực hiện tính toán kết quả và trả về một collection như Array về cho driver node. Và nếu dữ liệu của collection này quá lơn vượt qua bộ nhớ chính của driver node thì sẽ gây lỗi tràn bộ nhớ cho chương trình.
Lazy evaluation:
- Ban đầu RDD được tạo qua Transformation chỉ như một metadata chỉ dẫn cách tính toán dữ liệu tạo nên RDD đó.
- Dữ liệu trên các RDD chỉ được thực sự tính toán khi gọi Action
- Thao tác loading dữ liệu cũng là Lazy Evaluation
- Spark dùng Lazy Evaluation để tối ưu tính toán. Bằng cách nhóm các thao tác lại, xây dựng lược đồ tính toán.
Do vậy không đảm bảo một thao tác map phức tạp sẽ hiệu quả hơn chuỗi thao tác đơn giản.
c. Persistence (Caching)
- Dùng khi một RDD được sử dụng nhiều lần
- Kết quả được tính một lần và các node lưu lại partition tương ứng. Các partition này có bản sao và cơ chế chịu lỗi.
- Có nhiều mức độ persistence dựa vào in memory or on disk
=> Tránh persist quá nhiều khiến tràn bộ nhớ, unpersist() khi RDD không sử dụng nữa.
2. Làm việc với Pair RDD:
a. Tạo một Pair RDD:
Pair RDD thường được tạo qua Map operation hoặc bạn đọc từ nguồn bên ngoài mà dữ liệu đến dạng tuple2.
Ví dụ:
val lines22 = sc.textFile(“data1.txt”)
val pairs22= lines22.map(s => (s, 1))
b. Transformation Oparation:
Giả sử ta có đầu vào : rdd {(1, 2), (3, 4), (3, 6)}
- reduceByKey(func) - kết hợp các giá trị có cùng key.
- Ví dụ : rdd.reduceByKey( (x, y) => x + y)
- Kết quả {(1, 2), (3, 10)}
- groupByKey() - nhóm các giá trị có cùng key.
- Ví dụ: rdd.groupByKey()
- Kết quả {(1, [2]), (3, [4, 6])}
- mapValues(func) - sử dụng một func thay đổi giá trị của value.
- Ví dụ : rdd.mapValues(x => x+1)
- Kết quả: {(1, 3), (3, 5), (3, 7)}
- flatMapValues(func) - giống mapValues nhưng trả về một iterator các value có cùng key.
- Ví dụ : rdd.flatMapValues(x => (x to 5)
- Kết quả : {(1, 2), (1, 3), (1, 4), (1, 5), (3, 4), (3, 5)}
- keys() - lấy ra các giá trị key
- Ví dụ: rdd.keys()
- Kết quả : {1, 3, 3}
- values() - lấy ra các giá trị value
- Ví dụ: rdd.values()
- Kết quả {2, 4, 6}
- sortByKey() - trả về một rdd được sắp xếp theo key.
- Ví dụ : rdd.sortByKey()
- Kết quả: {(1, 2), (3, 4), (3, 6)}
- combineByKey(createCombiner, mergeValue, mergeCombiners) - cho phép trả về 1 kết quả không cùng loại với kết quả đầu vào.
- creatCombiner: cung cấp 1 func để tạo ra một giá trị mới từ một giá trị cũ cho một accumulator
- mergeValue : cung cấp 1 func để tạo ra một giá trị mới có cùng key cho accumulator
- mergeCombiners: kết hợp các accumulator ở các phân vùng khác nhau
- Ví dụ: giả sử ta có đầu vào : rdd {(1, 2), (3, 4), (3, 6)}
- val result = input.combineByKey( (v) => (v, 1), (acc: (Int, Int), v) => (acc + v, acc + 1), (acc1: (Int, Int), acc2: (Int, Int)) => (acc1 + acc2, acc1 + acc2) ).map{ case (key, value) => (key, value / value.toFloat) }
- Kết quả đầu ra sẽ là {(1,2),(3,5)}
c. Transformation Operation trên 2 pair RDDs:
Giả sử ta có đầu vào : rdd = {(1, 2), (3, 4), (3, 6)} other = {(3, 9)}
- subtractByKey()
- Ví dụ : rdd.subtractByKey(other) - xóa dữ liệu có key trong other -> Kết quả: {(1, 2)}
- join() - thực hiện ghép nối 2 rdd.
- Ví dụ: rdd.join(other)
- Kết quả: {(3, (4, 9)), (3, (6, 9))}
- rightOuterJoin()
- Ví dụ : rdd.rightOuterJoin(other) - thực hiện ghép nối 2 bảng với key là bảng other -> Kết quả:{(3,(Some(4),9)), (3,(Some(6),9))}
- leftOuterJoin(func) - ngược với rightOuterJoin
- Ví dụ : rdd.leftOuterJoin()
- Kết quả: {(1,(2,None)), (3, (4,Some(9))), (3, (6,Some(9)))}
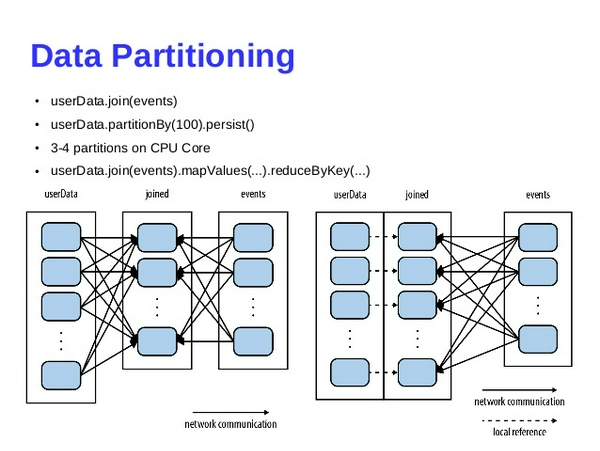
- Data Partitioning
d. Action Operation:
Giả sử ta có đầu vào : rdd = {(1, 2), (3, 4), (3, 6)}
- countByKey() - đếm số lượng phần tử của mỗi key.
- Ví dụ : rdd.countByKey() -> kết quả: {(1, 1), (3, 2)}
- lookup(key) - đưa ra các value của một key.
- Ví dụ : rdd.lookup(key)(3) -> kết quả:[4, 6]
- collectAsMap() - đưa kết quả của RDD thành một Map.
- Ví dụ : rdd.collectAsMap() -> kết quả: Map{(1, 2), (3, 4), (3, 6)}
3. Các nội dung chuyên sâu:
Đôi khi chúng ta muốn sử dụng các biến bên ngoài của chương trình driver (Ví dụ như các config, giá trị khởi tạo) trong transformation. Điều này là hoàn toàn có thể. Thông thường các bản sao của biến đó sẽ được gửi từ driver node đến worker node. Nhưng những thay đổi trên biến này không được tập hợp lại trên driver node. Để khắc phục điều này Spark cung hai share variable thông dụng:
- Accumulators
- Broadcast Variables
a. Accumulators Variables:
- Biến tập hợp giá trị từ các worker nodes trở về driver node
- Thường dùng đếm các sự kiện xảy ra trong quá trình execute ở worker node (Nghĩa là action phải đã được gọi)
- Tương tự reduce nhưng là phiên bản thực hiện đơn giản hơn
- Gửi update thay đổi cho driver node một lần
- Chú ý khi thực hiện lại một action khác thì có thể dẫn đến chạy lại transformation chứa code update accumulator.
=> Chỉ nên dùng cho mục đích debug
Ưu điểm: Không gây ra nhiều giao tiếp truyền thông gây ra bởi update biến. Chỉ lưu lại lượng thay đổi sau đó gửi 1 lần về driver node.
b. Broadcast Variables:
- Được gửi từ driver node với cơ chế giống BitTorrent cho worker node
- Các task ở worker không thể thay đổi giá trị biến
- Chọn các lib serialization tốt (như Kryo) khi kích thước broadcast variable lớn (tránh bottleneck)
Ví dụ: Gửi bản lookup giá model điện thoại
4. Kết luận:
Trên đây là những tổng hợp và ví dụ diễn giải của tôi về cách hoạt động và việc lập trình Spark với RDD và Pair RDD. Đồng thời giới thiệu qua những chủ để chuyên sâu trong spark. Nội dung của bài viết này chủ yêu được lấy từ cuồn sách: Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia - Learning Spark_ Lightning-Fast Big Data Analysis (2015, O'Reilly Media). Bạn đọc có thể tìm cuốn sách trên để tìm hiểu chi tiết thêm những chủ để khác.