Vấn đề Imblanced data trong các bài toán classification !
Điều gì xảy ra trong bộ dữ liệu trong các lĩnh vực như: phát hiện gian lận trong ngân hàng, đấu thầu thời gian thực trong tiếp thị hoặc phát hiện xâm nhập trong mạng, nói chung? Dữ liệu được sử dụng trong các lĩnh vực này thường có dưới 1% các sự kiện hiếm hoi, nhưng "thú vị" (ví dụ: những kẻ lừa đảo sử dụng thẻ tín dụng, người dùng nhấp vào quảng cáo hoặc máy chủ bị hỏng quét mạng của nó). Tuy nhiên, hầu hết các thuật toán học máy không hoạt động tốt với các bộ dữ liệu không cân bằng. Bảy kỹ thuật sau đây có thể giúp bạn, đào tạo một bộ phân loại để phát hiện ra lớp bất thường.

1.Sử dụng các chỉ số đánh giá phù hợp
Áp dụng các chỉ số đánh giá không phù hợp cho mô hình được tạo bằng cách sử dụng dữ liệu mất cân bằng có thể nguy hiểm. Hãy tưởng tượng dữ liệu đào tạo của chúng ta là dữ liệu được minh họa trong biểu đồ ở trên. Nếu độ chính xác được sử dụng để đo lường độ tốt của mô hình, mô hình phân loại tất cả các mẫu thử thành “0” sẽ có độ chính xác tuyệt vời (99,8%), nhưng rõ ràng, mô hình này sẽ không cung cấp bất kỳ thông tin giá trị nào cho chúng ta. Trong trường hợp này, các chỉ số đánh giá thay thế khác có thể được áp dụng như:
Độ chính xác / độ đặc hiệu: bao nhiêu trường hợp được chọn có liên quan. Nhớ lại / Độ nhạy: bao nhiêu trường hợp có liên quan được chọn.
Điểm số F1: trung bình hài hòa của độ chính xác và thu hồi.
MCC: hệ số tương quan giữa phân loại nhị phân được quan sát và được dự đoán.
AUC: mối quan hệ giữa tỷ lệ thực dương và tỷ lệ dương tính giả.
2. Lấy mẫu lại tập huấn luyện
Ngoài việc sử dụng các tiêu chí đánh giá khác nhau, người ta cũng có thể làm việc để có được tập dữ liệu khác nhau. Hai cách tiếp cận để tạo ra một tập dữ liệu cân bằng trong một tập dữ liệu không cân bằng là under-sampling và oversampling.
2.1 Under-sampling
Việc lấy mẫu làm cân bằng tập dữ liệu bằng cách giảm kích thước của lớp trội. Phương pháp này được sử dụng khi số lượng dữ liệu là đủ. Bằng cách giữ tất cả các mẫu trong lớp hiếm và chọn ngẫu nhiên một số trong lớp trội, một tập dữ liệu cân bằng mới có thể được lấy ra để lập mô hình tiếp theo.
2.2 Over-sampling
Ngược lại, oversampling được sử dụng khi số lượng dữ liệu không đủ. Nó cố gắng cân bằng số liệu bằng cách tăng kích thước của các mẫu hiếm. Thay vì loại bỏ các mẫu phong phú, các mẫu hiếm mới được tạo ra bằng cách sử dụng ví dụ: lặp lại, bootstrapping hoặc SMOTE (Synthetic Minority Over-Sampling Technique) [1]. Lưu ý rằng không có lợi thế tuyệt đối của một phương pháp resampling hơn một phương pháp khác. Áp dụng hai phương thức này phụ thuộc vào trường hợp sử dụng mà nó áp dụng cho và tập dữ liệu chính nó.
3. Sử dụng K-fold Cross-Validation đúng cách
Đáng chú ý là cross-validation phải được áp dụng đúng cách trong khi sử dụng phương pháp over-sampling để giải quyết các vấn đề mất cân đối. Hãy ghi nhớ rằng over-sampling phải quan sát các mẫu hiếm và áp dụng bootstrapping để tạo ra dữ liệu ngẫu nhiên mới dựa trên một hàm phân phối. Nếu cross-validation được áp dụng sau khi over-sampling, về cơ bản những gì chúng ta đang làm là đưa mô hình của chúng ta bị overfitting trên một kết quả bootstrapping đặc biệt. Đó là lý do tại sao cross-validation phải luôn được thực hiện trước khi over-sampling, cũng giống như cách lựa chọn tính năng được thực hiện. Chỉ bằng cách resampling dữ liệu nhiều lần, ngẫu nhiên có thể được đưa vào tập dữ liệu để đảm bảo rằng sẽ không bị vấn đề overfitting.
4. Tập hợp các tập dữ liệu được lấy mẫu khác nhau
Cách dễ nhất để khái quát hóa mô hình thành công là sử dụng nhiều dữ liệu hơn. Vấn đề là các bộ phân loại out-of-the-box như hồi quy logistic hoặc rừng ngẫu nhiên có xu hướng tổng quát hóa bằng cách loại bỏ lớp hiếm. Một thực hiện tốt nhất là xây dựng n mô hình sử dụng tất cả các mẫu của các mẫu hiếm và n-khác biệt của lớp phong phú. Do bạn muốn tập hợp 10 mô hình, bạn sẽ giữ nguyên ví dụ: 1.000 trường hợp hiếm hoi và lấy mẫu ngẫu nhiên 10.000 trường hợp của lớp học
phong phú. Sau đó, bạn chỉ cần chia 10.000 trường hợp trong 10 khối và đào tạo 10 mô hình khác nhau.
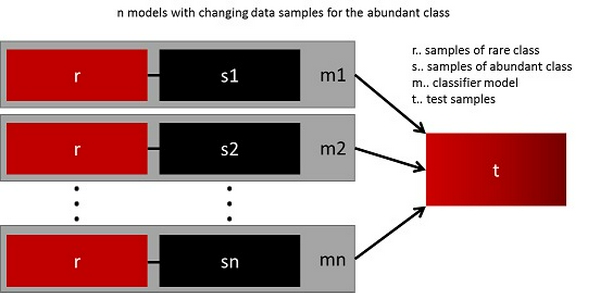
Cách tiếp cận này đơn giản và hoàn toàn có thể mở rộng theo chiều ngang nếu bạn có nhiều dữ liệu, vì bạn chỉ có thể đào tạo và chạy các mô hình của mình trên các nút cụm khác nhau. Các mô hình kết hợp cũng có xu hướng khái quát hóa tốt hơn, khiến cho phương pháp này dễ xử lý.
5. Lấy mẫu với các tỷ lệ khác nhau
Cách tiếp cận trước đó có thể được tinh chỉnh bằng cách thay đổi tỷ lệ giữa lớp hiếm và phong phú. Tỷ lệ tốt nhất phụ thuộc nhiều vào dữ liệu và các mô hình được sử dụng. Nhưng thay vì đào tạo tất cả các mô hình với tỷ lệ tương tự nhau, có thể tổng hợp các tỷ lệ khác nhau. Vì vậy, nếu 10 mô hình được đào tạo, có thể điều chỉnh để một mô hình có tỷ lệ 1: 1 (hiếm: phong phú) và một mô hình khác với 1: 3, hoặc thậm chí 2: 1. Tùy thuộc vào mô hình được sử dụng này có thể ảnh hưởng đến trọng lượng mà một lớp được.
6. Phân cụm lớp phong phú
Một cách tiếp cận đã được đề xuất bởi Sergey trên Quora [2]. Thay vì dựa vào các mẫu ngẫu nhiên để đại diện cho sự đa dạng của các mẫu đào tạo, ông đề nghị phân cụm các lớp phong phú vào r nhóm. Đối với mỗi nhóm, chỉ có medoid (center of cluster) được giữ lại. Mô hình này sau đó được đào tạo với lớp hiếm và chỉ các medoid.
7. Thiết kế mô hình của riêng mình
Tất cả các phương pháp trước đây tập trung vào dữ liệu và giữ mô hình như là một thành phần cố định. Nhưng trên thực tế, không cần phải lấy mẫu lại dữ liệu nếu mô hình phù hợp với dữ liệu không cân bằng. XGBoost nổi tiếng đã là một điểm khởi đầu tốt nếu các lớp học không bị lệch quá nhiều, bởi vì nó tạo một bộ các bags không bị mất cân bằng. Sau đó một lần nữa, dữ liệu được lấy lại, nó chỉ xảy ra một cách bí mật. Bằng cách thiết kế một hàm chi phí mà đang phân loại sai phân loại của lớp hiếm hơn phân loại sai của lớp phong phú, có thể thiết kế nhiều mô hình tự nhiên tổng quát ưu tiên lớp hiếm. Ví dụ, tinh chỉnh một SVM để trừng phạt phân loại sai của lớp hiếm.
[1]
[2]
Source : www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
machine learning
,trí tuệ nhân tạo
Rất hữu ích! Cảm ơn bạn đã dịch! :D
Người ẩn danh
Rất hữu ích! Cảm ơn bạn đã dịch! :D