Giới thiệu về thư viện KERAS trong lập trình Machine Learning

Machine Learning đang ngày càng phát triển và đi vào thực tế, thoát ra khỏi sách vở, càng ngày lại càng có nhiều ứng dụng thương mại phổ biến rộng rãi. Nhờ nhu cầu càng ngày càng tăng của ML mà có rất nhiều thư viện được tạo ra để giúp đỡ cho những người mới học về ML như Keras, TFLearn, PyTorch...
Ở bài học này, mình sẽ trình bày hướng dẫn về cách triển khai ML bằng cách sử dụng Keras.
Nên học cái gì?
Đối với những bạn mới bắt đầu với ML thì mục tiêu chính của các bạn là hiểu bản chất của ML càng sớm càng tốt chứ đừng tìm hiểu luôn về cách code ML thế nào. Trong quá trình học, bạn không nên tập trung vào những câu hỏi như "Phải code như thế nào?" mà nên tập tring vào những câu hỏi như: "Điều gì sẽ xảy ra khi ta tăng các hidden layer lên?", "Làm thế nào để phân biệt được một tập dữ liệu xấu và một tập dữ liệu tốt?" "Tại sao lại cần phải chia bộ dữ liệu thành bộ test và bộ train?", "Với bộ dữ liệu của tôi thì kỹ thuật ML nào phù hợp hơn?" hoặc một số câu hỏi khác đặc biệt là những câu hỏi liên quan đến cách mà ML hoạt động. Điều tôi nói trên thực sự quan trọng vì ML không phải về mã code, mà là về cách bạn chọn kỹ thuật của ML và khắc phục sự cố nếu mô hình thực tế của bạn kém.
Theo quan điểm của tôi, ML giống như là nghệ thuật hơn là lập trình, giống như tất cả những nghệ thuật khác, cách duy nhất để bạn học và trở nên tốt hơn là tập trung vào cốt lõi của nghệ thuật chứ không phải công cụ tạo ra nghệ thuật. Pablo picasso đã có thể đưa nghệ thuật vào bất cứ thứ gì như nhà điêu khắc, tranh vẽ, và còn nhiều hơn thế nữa, tôi tin rằng ông ấy có thể biến rác thành nghệ thuật. Ông ấy có thể làm điều đó không phải vì ông lo lắng về những công cụ hoặc phương thức nào mà ông ấy sử dụng, mà bởi vì ông hiểu được nghệ thuật vì vậy mà ông có thể thể hiện bất kỳ cảm xúc theo bất kỳ phương thức nào (dù cho điêu khắc hay vẽ,...). Ở bài viết này, tôi muốn bạn trở thành một picasso trong một khoảnh khắc và không cần lo ngại về code và tập trung nhiều hơn vào vấn đề của bạn và đưa ra cách giải quyết bằng ML. Vì vậy, đối với những người mới, tôi khuyên bạn nên sử dụng Keras vì cú pháp rất đơn giản và bạn có thể dễ dàng sử dụng cấu trúc của ML một cách đơn giản, ngoài ra tài liệu hướng dẫn của Keras cũng khá tường tận và chi tiết so với các thư viện khác.
Trước đó, hãy cùng tìm hiểu về một số thuật ngữ ML
Vấn đề lớn nhất đối với những người mới học để hiểu về bản chất của ML qua những bài báo hoặc video là thuật ngữ. Những thuật ngữ đó có thể khó hiểu với bạn. nhưng trong bài viết này tôi sẽ giải thích một số thuật ngữ theo cách đơn giản nhất có thể.
- Training: là quá trình dạy cho chương trình cách tạo ra một số đầu ra dựa trên đầu vào và đầu ra đã biết, Bạn cũng có thể tưởng tượng giống như con người khi học cách chơi cờ vua từ kinh nghiệm vì vậy mà ta có thể đánh bại đối thủ tiếp theo dựa vào kinh nghiệm đã thắng đối thủ trước đó. Đối với máy tính, quá trình này thường được gọi là training và kinh nghiệm chính là từ bộ dữ liệu đã có sẵn.
- Supervised Training: quá trình training bằng cách sử dụng bộ dữ liệu theo cặp input-output. Trong kỹ thuật training này, mục tiêu là map mọi đầu vào đã biết với mọi đầu ra đã biết. Ví dụ như vấn đề phân loại (classification), vấn đề regression (predict-dự đoán). Hầu hết ML sử dụng phương pháp này vì dễ thực hiện.
- Unsupervised training: quá trình training bằng cách sử dụng dữ liệu mà chỉ có input, không hề có output (label). Mục tiêu của phương thức training này là để hiểu hoặc mô hình hóa cấu trúc của bộ dữ liệu. Ví dụ phân vùng (clustering).
- Model: hiểu đơn giản thì nó là kết quả của quá trình training. Bạn có thể tưởng tượng nó như một hộp đen sẽ cung cấp cho một đầu ra nhất định khi bạn đưa một đầu vào vào, và quá trình training chỉ là một số phương pháo để điều chỉnh hộp đen đó sao cho tìm được kết quả đầu ra mong muốn.
- Convergence: điều kiện trong quá trình training, nơi model có thể tạo ra đầu ra chính xác cho mọi đầu vào trong tập dữ liệu. Giống như trong ví dụ cờ vua của chúng ta, chúng ta có thể tưởng tượng nó như là điều kiện để một người chơi có thể đánh bại bất cứ ai trong buổi training. Tính hội tụ cao không có nghĩa là mô hình có khả năng dự đoán chính xác bất cứ đầu vào nào, giống như người chơi cờ vua không phải lúc nào cùng thắng khi họ phải đối mặt với một người mà họ chưa bao giờ chơi mặc dù họ có thể luôn luôn thắng người chơi cùng mình.
- Test: quá trình đánh giá kết quả training tốt thế nào bằng cách sử dụng tập dữ liệu bên ngoài tập dữ liệu đã biết được sử dụng trong quá trình training. Giống như trong thực tế, mục đích của một người tập chơi cờ vua là để đối mặt với một đối thủ mới chứ không chỉ là đối thủ đã gặp trong quá trình training. Mục tiêu chính là đánh bại bất kỳ ai ngay cả khi không được tập chơi với họ, Do đó để kiểm tra những gì mà bạn đã training thì cần phải dùng bộ dữ liệu hoàn toàn không có trong bộ dữ liệu training, Đó là lý do tại sao chúng tôi lại chia dữ liệu thành bộ test và bộ train. vì chúng ta cần phải biết là mô hình ML tốt thế nào khi nó đối mặt với đầu vào bên ngoài dữ liệu đã biết.
- Overfitting: Giống như một người đánh bại mọi người trong quá trình training nhưng nực cười là lại không đánh thắng bất cứ một ai ngoài quá trình training cả. ML model cũng có thể thực hiện tốt trong quá trình training nhưng lại kém trên dữ liệu thử nghiệm và thực tế. Điều này là do dữ liệu thử nghiệm là một dữ liệu mới và mày không bao giờ phải gặp trước đây. Trong thuật ngữ, overfittiong là điều kiện mà máy không tổng quát hóa mô hình và chỉ tạo ra một mô hình chuyên nghiệp cho quá trình training.
- Features: Đó là biều diễn đầu vào dưới dạng số, mảng hoặc bất kỳ thứ gì mà máy tình có thể xử lý được. Mục tiêu chính của việc sử dụng biểu diễn feature là tạo ra dữ liệu duy nhất và được tính bằng máy. Ví dụ, nếu dữ liệu đưa vào là một hình ảnh, chắc chắn chúng ta cần phải chuyển nó thành mảng màu. Trong trường hợp này, feature mày đỏ sẽ thế nào? màu xanh thế nào? và mày xanh thì thế nào? hoặc RGB. Trong ví dụ khác, nếu input là text, máy tính cũng không thể tính toán văn bản, vì vậy cần một phương thức để biểu diễn dữ liệu như kỹ thuật Word2Vec và bow. Nếu chúng ta sử dụng bow, feature thì sẽ thường là một từ trong một câu, trong khi đó nếu ta sử dụng word2vec thì feature sẽ thường là cột trong matrix.
Chúng ta sẽ làm gì tiếp theo?
Sau khi đã hiểu về định nghĩa ML, giờ là thời gian để thực hành sử dụng Keras. Để hiểu rõ hơn, chúng ta sẽ sử dụng Keras để giải quyết bài toán phân loại text. Tôi tin rằng bài toán phân loại text sẽ cung cấp cho các bạn thông tin chi tiết hơn vì nó bao gồm cả các kỹ thuật thường được sử dụng để triển khai giải quyết các vấn đề khác nữa. Bằng cách sử dụng bộ
- tensorflow==1.4.1
- Keras==2.1.3
- pandas==0.22.0
- numpy==1.14.0
- scikit_learn==0.19.1
Kỹ thuật ML mà chúng ta sẽ sử dụng trong bài này là mạng nơ-ron với một hidden layer chứa 5k nơ-ron. Cấu trúc của mạng nơ-ron của chúng ta có thể được nhìn thấy dưới đây:
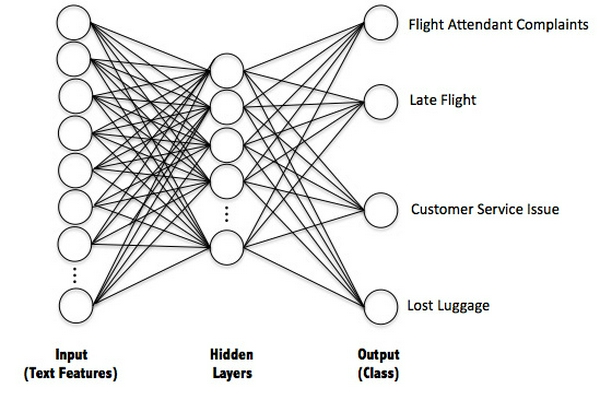
Tôi có thể quyết định số lượng của nơ-ron tùy ý. vì vậy mà số lượn nơ-ron có thể thay dổi tùy ý theo bạn. Những điều chính bạn cần phải hiểu khi quyết định số nơ-ron là số nơ-ron càng lớn thì mô hình của bạn càng phù hợp với dữ liệu training, nhưng điều này cũng dẫn đến overfit. Chính vì vậy mà việc quyết định số lượng nơ-ron sẽ được quyết định tùy ý. tuy nhiên thì có một số thuật toán
Chuyển đổi từ text sang feature sử dụng BOW.
Giống như những gì tôi đã giải thích trước đó về ML dictionary, nếu dữ liệu của chúng ta bao gồm cả text, chúng ta cần phải có một phương thức để chuyển đổi nó về một dạng khác mà máy tính có thể nhận thấy được, thường tốt nhất là để dạng mảng số. Vì vậy, chúng ta sẽ sử dụng bag-of-word (từng từ) để trích xuất đối tượng từ input text.
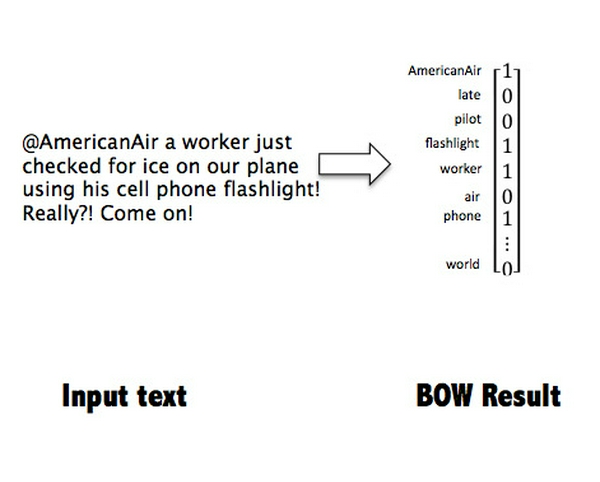
Về cơ bản, BOW sẽ tạo ra một danh sách các từ xuất hiện trong dữ liệu của chúng ta và trong mỗi câu, từ đó có xuất hiện trong từ điển thì giá trị của nó là 1, và là 0 nếu không xuất hiện. Bạn hãy xem hình minh họa dưới đây để dễ hiểu hơn.
Để tạo ra từ điển và chuyển từ câu sang mảng, ta sử dụng

Sau khi đã tạo xong bộ từ vựng vocabulary, tiếp theo chúng ta sẽ convert một câu sang bow:

Tạo mạng nơ-ron
Giờ thì tôi sẽ hướng dẫn các bạn sử dụng Keras để tạo mới một mạng nơ-ron như đã nói từ trước. Để tạo mạng nơ-ron sử dụng Keras, chúng ta sẽ sử dụng model Keras Sequential và tạo layer bằng cách thêm layer Dense vào model sequential như là code dưới đây:

Như các bạn đã thấy ở trên, tạo một layer trong Keras chỉ cần một dòng code. Nếu ta sử dụng Tensorflow hoặc Theano thì có lẽ cần một đoạn code như trên mà chỉ tạo ra một lớp layer.
Trong layer Dense đầu tiên bao gồm 1 hidden layer, tôi truyền vào 3 tham số:
- 5000: số lượng nơ-ron của layer đó.
- input_shape: đây là kích thước của feature mà ta đã tạo ra ở trên.
- relu: như là hàm kích hoạt (activation function)
Bạn cần phải nhớ rằng ta chỉ cần định nghĩa input_shape ở layer đầu tiên bở vì các layers Keras tiếp theo nó sẽ tự động suy luận từ layer trước nó.
Chắc hẳn các bạn sẽ tự hỏi rằng relu là gì và hàm kích hoạt là gì. Nói một cách đơn giản, hàm kích hoạt là một trong những thành phần điều chỉnh đầu ra của mạng nơ-ron. Ví dụ, đầu ra của mạng nơ-ron chúng ta định nghĩa là không nhận giá trị âm, nhưng output của mạng nơ-ron lại là -0.87. Trong kịch bản này, ta cần chuyển đổi -0.87 về dạng số dương. Nếu ta sử dụng hàm kích hoạt, nó có nghĩa là: f(x) = max(0,x). Hay nói đơn giản hơn thì cách hoạt động của relu là chuyển tất cả những số âm thành số 0 còn số dương thì giữ nguyên. Một số hàm kích hoạt khác ta có thể sử dụng trong Keras như softmax, tank, linear,... Để biết thêm chi tiết, mời bạn check qua
Kayer thứ 2 mà tôi đã thêm vào là dropout dùng để ngăn chặn overfitting. Trên lý thuyết,
Với layer cuối cùng, chúng ta phải đảm bảo rằng số lượng nơ-ron bằng với số lượng class mà chúng ta có ở output. Tại sao lại phải như vậy? Vâng, trong ví dụ này, tôi sẽ sử dụng one-hot để biểu diễn class, chính vì vậy mà số lượng output của mạng nơ-ron cần phải bằng với size của ma trận one-hot.
Sau khi định nghĩa được các layer cho model, trong Keras, ta cần compile model và định nghĩa hàm loss, optimizer và metrics. Loss function sẽ tính toán được hiệu năng model của chúng ta trong quá trình training và quá trình học. Loss càng nhỏ thì có nghĩa là model của chúng ta càng hội tụ với dữ liệu training. Optimizer là quá trình tối ưu trong ML, về nguyên tắc là làm giảm tổn thất, mất mát trong quá trình training. Vì việc optimizer là điều chỉnh việc cập nhật các trọng số trong mạng nơ-ron.
Train model
Để train model trong keras, chúng ta chỉ cần sử dụng

Đoạn code ở trên làm 2 việc chính là chuyển đổi từ text sang ma trận bow và chuyển đổi từ label sang ma trận one-hot. Lưu ý là Keras




Chú ý rằng kết thúc của dòng code, tôi đã thêm một đoạn code để lưu lại model đã train, weight và encoder, Chúng ta cần phải làm vậy vì nếu trong tương lai, ta muốn phân loại một dữ liệu mới thì ta chỉ cần tải lại mô hình đã được train thay vì train lại từ đầu.
Đánh giá Model
Để đánh giá model chúng ta có thể sử dụng Keras function, nhưng tôi muốn hiển thị ra làm thế nào để load model từ file, vì vậy mà chúng ta sẽ đánh giá model sử dụng dòng code dưới đây:




Kết quả:
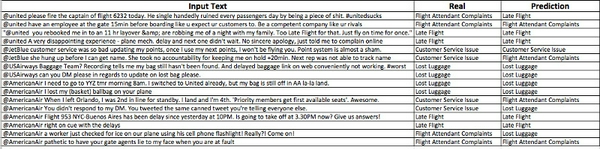
Từ 16 input đã sử dụng, ta phân loại và đoán đúng 11 (acc là 68.75%).
Bài trên đây tôi đã hướng dẫn các bạn cách sử dụng Keras và bài này tôi đã ví dụ về một bài toán phân loại văn bản. Mong rằng bài viết hữu ích cho các bạn.
Tham khảo: Getting Started with Keras