Mỗi ngày một bài báo: Hierarchical Attention Network cho phân loại tài liệu
Hôm nay, chúng ta sẽ cùng thảo luận về một bài báo của Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, và Eduard Hovy cho phân loại văn bản sử dụng mạng hierarchical attention networks.
Tóm tắt
Bài báo đề xuất một mạng hierarchical attention network với mục đích để phân loại văn bản. Model có hai đặc điểm đặc biệt:
- Cấu trúc phân cấp, phản ảnh theo cấu trúc phân cấp của văn bản.
- Với hai mức độ mà model sẽ chú trọng đến là từ và câu sẽ giúp cho những từ và câu có trong văn bản mà khác biệt với nội dung thì sẽ ít được chú ý hơn khi xây dựng biểu diễn văn bản.
Các thí nghiệm đã được tiến hành trên sáu nhiệm vụ phân loại văn bản lớn, điều này đã chứng minh rằng mô hình này vượt trội hơn so với những mô hình trước đó khá đáng kể.
Hierarchical Attention Networks
Tổng quan mô hình Hierarchical Attention Networks (HAN) được tôi đưa ra ở ảnh dưới đây. Bao gồm những thành phần sau: bộ mã hóa chuỗi từ, một layer word-level attention, một bộ mã hóa câu và một layer sentence-level attention.
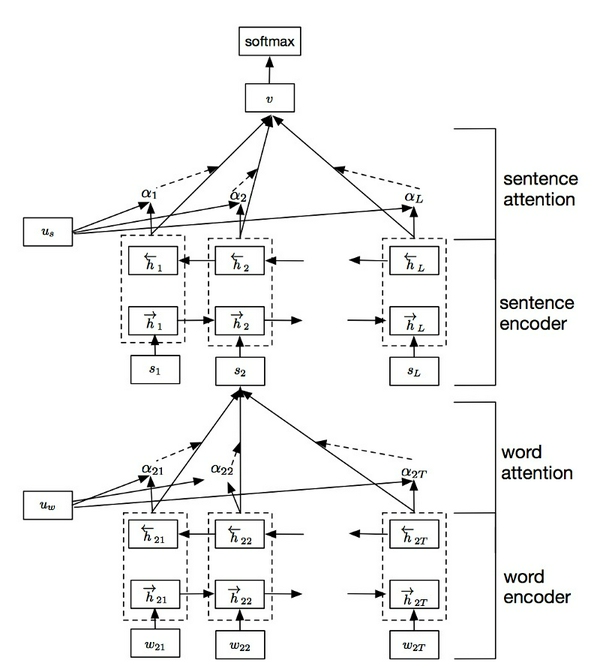
Giả sử một văn bản có L câu Si và mỗi câu chứa các từ Ti, Mô hình ban đầu sẽ chuyển văn bản đầu vào thành một vector, trên đó có một trình phân loại được xây dựng để thực hiện phân loại văn bản.
Word Encoder: Đầu vào là một câu với các từ Wit , t ∈ [0, T] . Từ được nhúng vào vector thông qua ma trận We. GRU hai chiểu được sử dụng để nhận chú thích của các từ bằng cách tóm tắt thông tin từ hai hướng cho các từ, do đó kết hợp thông tin theo ngữ cảnh trong chú thích.
Word Attention: Không phải tất cả các từ trong câu đều đóng góp như nhau tạo nên ý nghĩa của câu. Chính vì vậy, một cơ chế attention được sử dụng để trích suất những từ quan trọng đối với ngữ nghĩa của câu và sự biểu diễn của những thông tin đó, sau đó sẽ được tổng hợp lại để thành một vector câu.
Sentence Attention: Giống như Word Attention, không phải tất cả các câu đều có ý nghĩa trong việc phân loại văn bản. một lần nữa, cơ chế attention được sử dụng để đo tầm quan trọng của một câu.
Thực nghiệm:
Hiệu quả của mô hình này đã được đánh giá trên sáu bộ dữ liệu phân loại tài liệu quy mô lớn. Các bộ dữ liệu nayf có thể được phân loại thành hai tasks: phân loại theo cảm xúc và phân loại theo chủ đề. 80% dữ liệu dùng để training, 10% dùng để validation và 10% dùng để test.
Kết quả thực nghiệm trong bài báo đã chứng minh rằng mô hình này thực hiện tốt hơn đáng kể so với các mô hình trước đây. Việc hình dung các lớp attention này đã cho thấy mô hình của chúng ta có hiệu quả trong việc chọn ra các từ và câu quan trọng.
Tham khảo: A Paper A Day: #25 Hierarchical Attention Networks for Document Classification
trí tuệ nhân tạo
phương pháp này áp dụng attention ở mức từ và mức câu. liệu có cách nào áp dụng hiệu quả với short text chỉ gồm 1 hoặc 2 câu?
Nguyễn Vạn Nhã
phương pháp này áp dụng attention ở mức từ và mức câu. liệu có cách nào áp dụng hiệu quả với short text chỉ gồm 1 hoặc 2 câu?