Báo cáo phân loại văn bản sử dụng CNN, RNN & HAN (Phần 2: RNN & HAN)
Nếu chưa đọc PHẦN 1, các bạn hãy tham khảo để có một cái nhìn khách quan hơn nhé!
Dưới đây tôi sẽ tiếp tục trình bày những mô hình phân loại văn bản còn lại.
Phân loại văn bản sử dụng Recurrent Neural Network (RNN) - Mạng nơ-ron hồi quy:
Đây là một mạng nhân tạo có các két nối giữa các node tạo thành một đồ thị theo dọc theo một chuỗi.
Tôi sẽ vẫn sử dụng một bộ từ điển
Mô hình RNN dưới đây có thể trông khá phức tạp. RNN là một chuối các khối mạng nỏ-ron được liên kết với nhau như một chuỗi. Mối một khối sẽ chuyển một tin nhắn đến khối tiếp theo, tôi khuyên bạn nên đọc
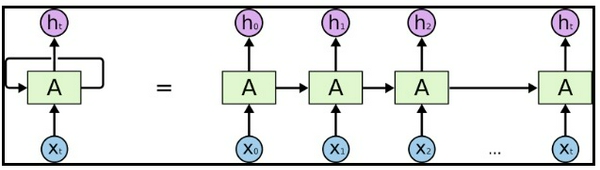
Giống như tiền xử lý CNN, dưới đây tôi cũng sử dụng Beautifil Soup. Tôi sẽ xử lý văn bản, đây là loại chuỗi. Thứ tự của các từ rất quan trọng đối với ý nghĩa của câu. Hi vọng RNN sẽ chú ý đến điều quan trọng này.
Để sử dụng Keras trong bộ dữ liệu văn bản, đầu tiên ta cần phải tiền xử lý nó. Trong đây, tôi đã sử dụng class Keras's Tokenizer. Đối số num_words là số lượng từ tối đa trong bộ từ điển.

Khi mà tokenizer đã được trang bị trên dữ liệu, chúng ta sẽ sử dụng nó để chuyển đổi từ string sang dạng chuỗi các số. Mỗi số sẽ đại diện cho vị trí mỗi từ trong từ điển.
Trong bài này, Tôi sẽ giải quyết vấn đề bằng cách sử dụng mạng nơ-ron hồi quy và attention dựa trên LSTM.
Bằng cách sử dụng bộ mã hóa LSTM, tôi dự định mã hóa tất cả thông tin của văn bản trước khi chạy mạng feed-forword để phân loại văn bản.
Dưới đây là hình ảnh từ
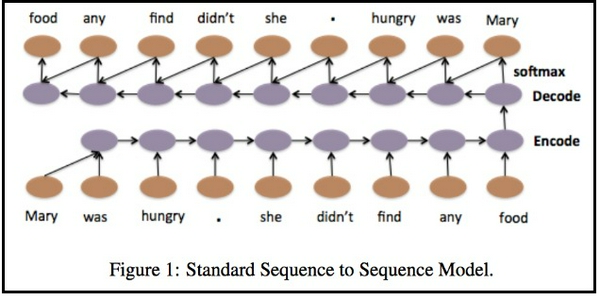
Image Reference :
Tôi đã sử dụng LSTM hai chiều và nối cả đầu ra cuối cùng của các đầu ra LSTM
Keras đã cung cấp một lớp vỏ gọi là bidirectional, điều này sẽ làm cho code mã hóa dễ dàng. Bạn có thể xem code mẫu ở

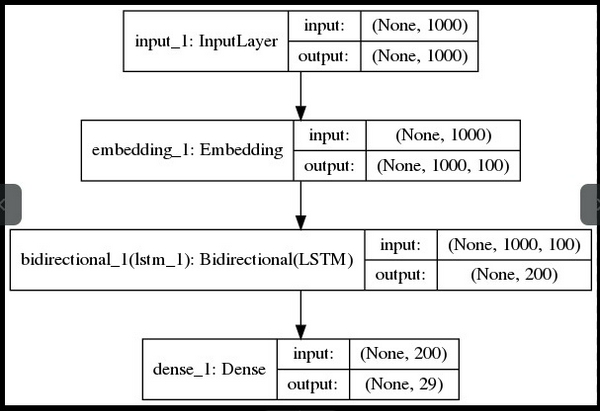
Và đây là kiến trúc mạng RNN:
Và cuối cùng, Phân loại văn bản sử dụng HAN (Mạng chú ý đến phân cấp)
Tôi đã lấy tài liệu tham khảo từ bài báo
Tôi xây dựng kiến trúc mạng LSTM, tôi phải xây dựng dữ liệu đầu vào là 3D thay vì 2D như ở 2 kiến trúc mạng bên trên.
Vì vậy mà input đầu vào sẽ có dạng [đánh giá mỗi batch, số câu, số từ của mỗi câu].
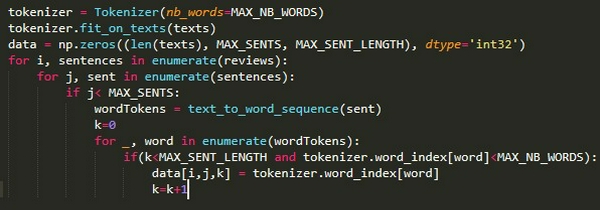
Tiếp theo, tôi sẽ sử dụng hàm TimeDistributed để xây dựng phân cấp layers đầu vào như ở bên dưới, để rõ hơn, bạn hãy đọc bài
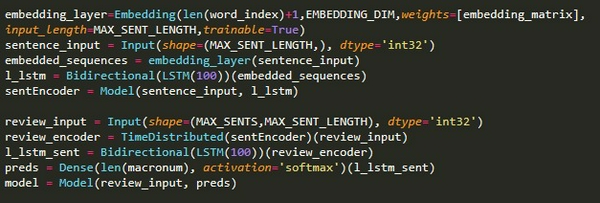
Dưới đây là kiến trúc HAN Model:
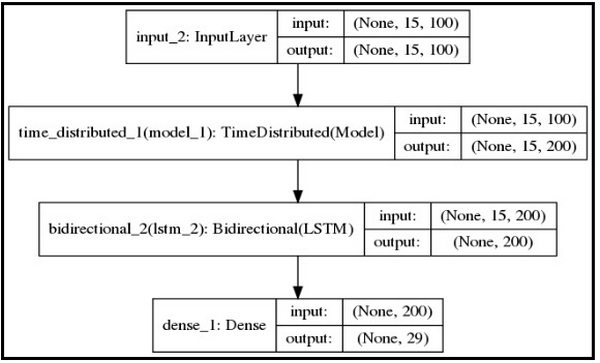
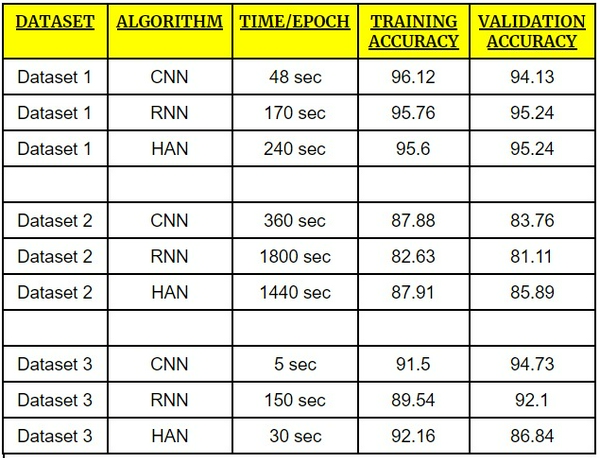
Kết quả tôi nhận được:
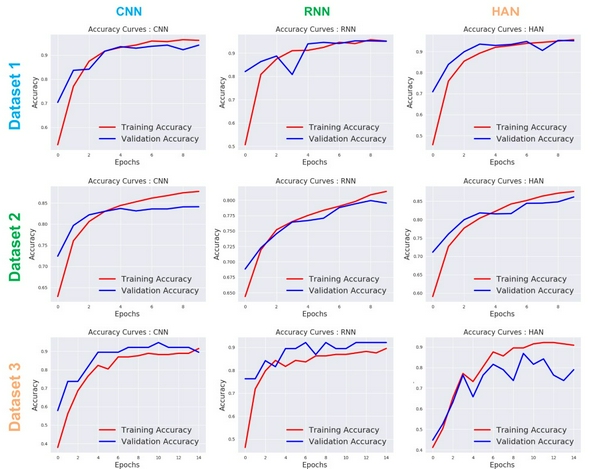
Dưới đây tôi đã plots hình ảnh của Accuracy 📈 và Loss 📉
Kết luận:
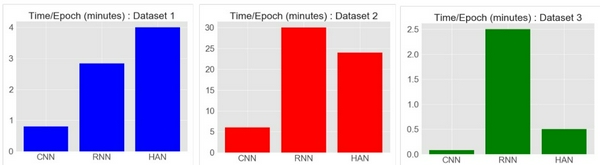
- Dựa trên các hình ảnh plot ở trên, CNN đã đạt được độ chính xác khá tốt với tính nhất quán cao, còn RNN và HAN đã được độ chính xác cao nhưng không nhất quán trong toàn bộ tập dữ liệu.
- RNN là kiến trúc tệ nhất để thực hiện các kịch bản có sẵn.
- CNN vượt trội hơn về thời gian training, tuy nhiên HAN có thể hoạt động tốt hơn CNN và RNN nếu ta có một tập dữ liệu lớn.
- Ở bộ data1 và data2, HAN đã thực hiện rất tốt khi có một bộ training lớn, tuy nhiên ở data3 thì HAN đã không làm được tốt như vậy (bộ dữ liệu training rất ít)
- Khi bộ dữ liệu training ít (data3) thì CNN đã đạt đc độ chính xác xác thực tốt nhất.
Cải tiến hiệu xuất:
Để đạt được kết quả tốt nhất, chúng ta có thể:
- Điều chỉnh thông số Hyper-Parameter: Hyper-parameters là các biến được đặt trước khi train và xác định cấu trúc mạng và cách mạng được train. (ví dụ như learning rate, bath size, num of epochs).
- Cải thiện tiền xử lý dữ liệu: Việc cải thiện tiền xử lý phụ thuộc vào tập dữ liệu của bạn như xóa một số ký tự đặc biệt, ...
- Sử dụng Dropout Layer: Đây là kỹ thuật thường được dùng để tránh overfitting do đó có thể cải thiện được mô hình của bạn,
Trên đây là toàn bộ bản so sánh của tôi về cả 3 model mà tôi đã sử dụng. Mong rằng nó sẽ giúp ích cho các bạn trong quá trình học tập NLP.
Tham khảo: Report on Text Classification using CNN, RNN & HAN